前回はキャッシュについて解説しました。
キャッシュをクリア
実際にキャッシュをクリアしてみましょう。クエリエディターに次のように入力して「実行」をします。
DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHE select * from Shain
このように,キャッシュのクリアコマンドに続けて,SQLを実施すると,キャッシュをクリアしてからSQLが実行されます。
これで1回目に検索した時と同じだけ検索時間がかかるようになりました。
今後は,SQLの前に必ずキャッシュクリアコマンドをつけて実行していきます。
検索条件ありで実行
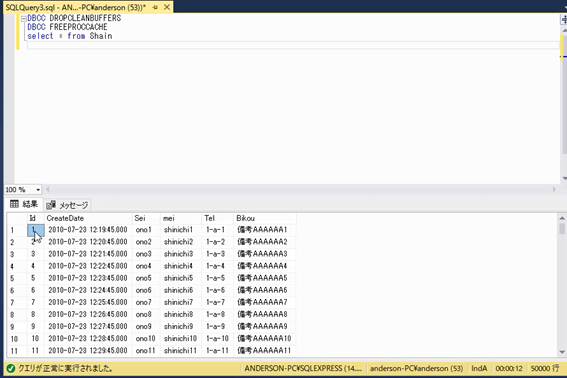
現在「社員テーブル」には5万件あり,全件検索を行うと,一番上の行に「Id」が「1」のデータが表示されています。ためしに,この1行目のデータをだけが検索結果に表示されるように,SQLを実行してみましょう。
DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHE select * from Shain where Id = 1
このようにSQLを実行すると,Idが「1」の列だけがヒットするため,検索結果は1件になるはずです。この一番上の1行を取得するのに,どれくらいの時間がかかると思いますか?1行なので一瞬で終わると思いますか?
それでは実際に実行してみましょう。
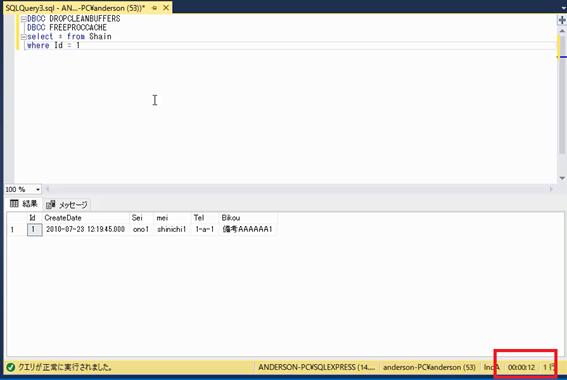
結果はなんと「12秒」です。全件検索したときと同じ時間がかかっています。「なんでこんなに時間がかかるの?」と思うかもしれませんが,検索処理の内部処理が分かれば,検索に時間がかかる理由が理解できるようになります。
実際の実行プラン
検索処理の内部処理は「実行プラン」で確認できます。画面上部の「実際の実行プランを含める」のボタンをクリックしてONにしてください。
この状態でSQLを実行すれば,内部でどのような経路で実行したかを確認することができます。
再度実行
「実際の実行プランを含める」をONにした状態で,もう一度SQLを実行します。先ほど同様に「12秒」ほど検索時間がかかりますが,出力結果に「実行プラン」というタブが表示されるようになります。
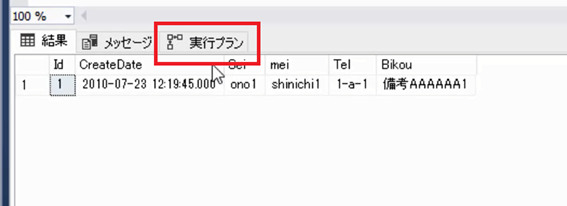
この「実行プラン」のタブを選択します。
実行プランタブ
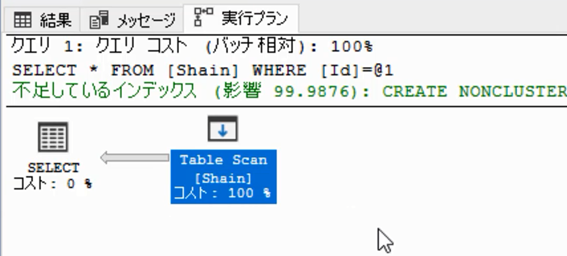
実行プランを表示すると,「TableScan」と表示されています。テーブルスキャンとは,「テーブルをすべて読みました」という意味です。
「スキャン」とは,スキャナーと同じで,端から端まですべて読み込むという処理です。「Idが1」のデータは1件しかないはずなのですが,端から端まで読み込んだという事です。なので,全件検索と同様の「12秒」という時間がかかっているわけです。
ちなみに検索条件なしの全件検索をして「実行プラン」を確認してみてください。今回と同様に「TableScan」(テーブルスキャン)になります。検索条件ありでもなしでもTableScanになっているという事です。
#S1_01_はじめに
#S1_02_インデックスとは
#S1_03_インデックスの有無実演
#S1_04_SQLServerのインストール
#S2_01_データベースとテーブルの作成
#S2_02_データの作成
#S2_03_全件検索
#S2_04_キャッシュとは
#S2_05_検索条件ありで検索
#S2_06_テーブルスキャンとは
#S2_07_インデックスの種類
#S2_08_非クラスター化インデックスの作成
#S2_09_非クラスター化インデックスの内部構造
#S2_10_インデックスのない列の検索とインデックスの有効化無効化
#S2_11_クラスター化インデックスの作成
#S2_12_クラスター化インデックスの内部構造
#S2_13_クラスター化インデックスの検索
#S2_14_インデックスの検索補足
#S2_15_付加列インデックス
#S2_16_プライマリキーとユニークキー
#S2_17_インデックス作成手順
#S2_18_インデックスの注意点
おわりに
参考図書
SQL
・SQL Server Transact-SQLプログラミング 実践開発ガイド
・SQLクックブック 第2版 ―データベースエキスパート、データサイエンティストのための実践レシピ集
・達人に学ぶSQL徹底指南書 第2版 初級者で終わりたくないあなたへ
・SQL Server 2016データベース構築・管理ガイド Enterprise対応
設計
内部構造
・アドバンストMS SQL SERVER 2008 構築・管理 (マイクロソフトコンサルティングサービステクニカルリファレンスシリーズ)