それでは今回は「非クラスター化インデックス」を作成していきます。
非クラスター化インデックスの作成
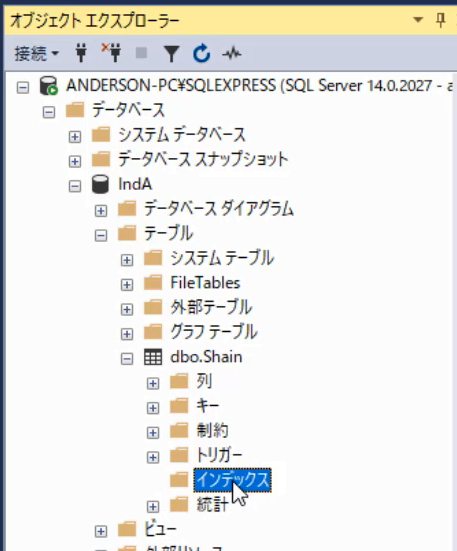
それでは非クラスター化インデックスの作成をしていきましょう。「IndA」の階層を開き,「テーブル」「Shain」の順に開いていきます。そうすると,その中に「インデックス」というフォルダーがあります。これも開いてもらうと,中には何も入っていないことが分かります。つまり,現状「Shain」テーブルには「インデックス」は存在しないという意味です。
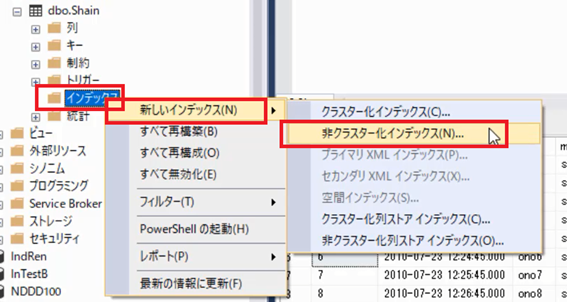
インデックスのフォルダーを右クリックして,「新しいインデックス」を選択し,「非クラスター化インデックス」をクリックします。
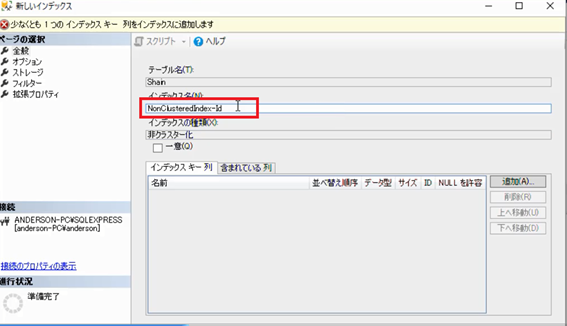
「新しいインデックス」の画面が表示されたら,まず「インデックス名」のところを,「NonClusteredIndex-Id」という名前にします。今回は「Id」での非クラスター化インデックスを作成するのでこういった名前にしました。実際現場で命名する場合は,現場の命名規約に合わせた名前を付けてください。
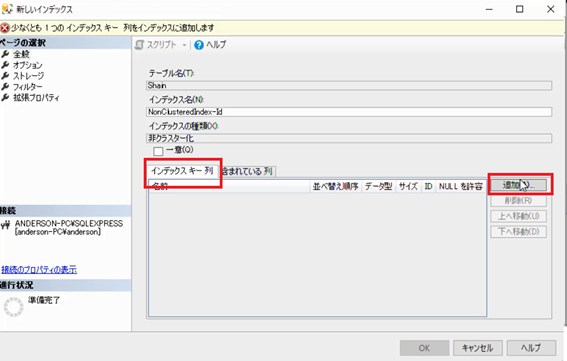
次に「インデックスキー列」のタブが選択されている状態で「追加」ボタンをクリックします。
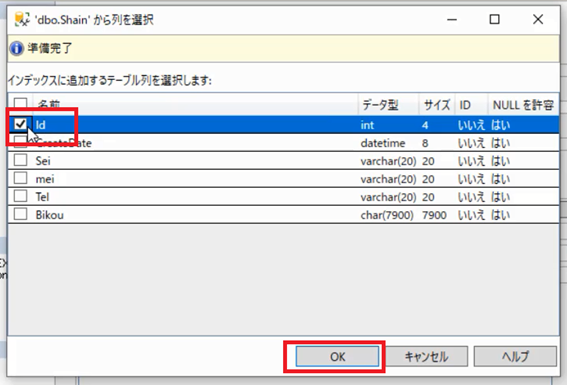
列の選択画面が表示されるので,「Id」のチェックボックスにチェックを入れて「OK」ボタンを押下します。
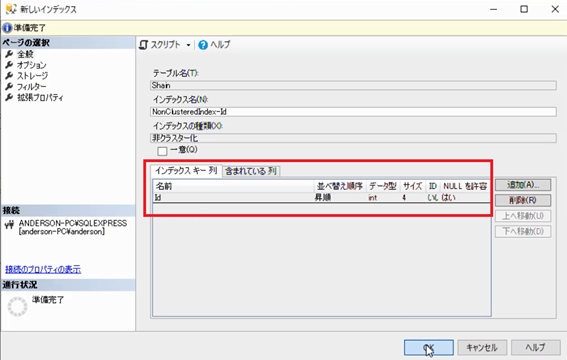
すると最初の画面に「Id」の列が追加された状態になるので,「OK」ボタンを押下し,非クラスター化インデックスを作成します。
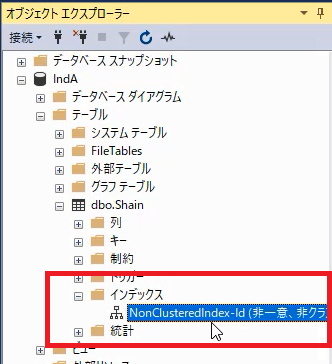
これで,「インデックス」フォルダーの中に,非クラスター化インデックスが作成されたことが確認できます。
検索条件ありで検索を実行
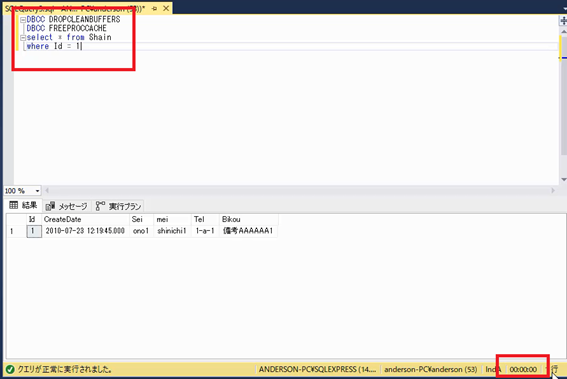
非クラスター化インデックスが作成された状態で,もう一度以前実施していた「Id=1」の検索条件で検索を実行してみます。
DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHE select * from Shain where Id = 1
すると,以前は12秒かかっていた検索が,1秒未満で完了しました。
実行プランの確認
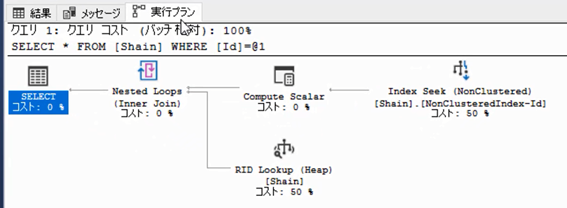
前回まではTableScanになっていましたが,今回は状況が変わっています。
IndexSeek
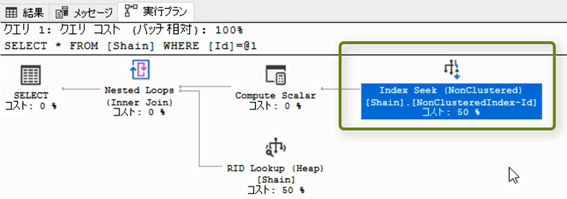
まず,IndexSeekになっているところに注目してください。
「Seek」とは「ピンポイントでデータを見つけました」という意味です。IndexSeekなので,「インデックスを使って,ピンポイントでデータを見つけた」という意味になります。いままでは「TableScan」でした。スキャンは「全部読んだ」という意味なのですが,「Seek」はピンポイントで見つけたという事なので,インデックスがうまく機能したという事です。
ScanかSeekか?
先述の通り,インデックスが機能しているかどうかをチェックする場合は,「Scan」か「Seek」のどちらなのかに注目してください。Scanなら全部読んだ,Seekならピンポイントで見つけられたという事なので,基本的には「Seek」になっていれば成功という事です。
RIDLookup
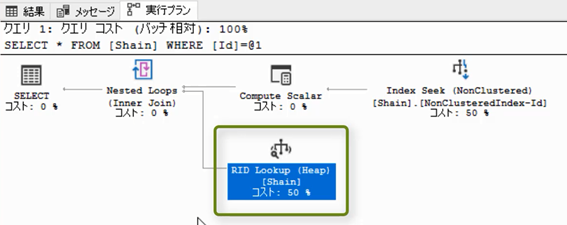
実行プランにはIndexSeekのほかに「RIDLookup」というものも存在します。
これは,非クラスター化インデックスの内部構造が分からないと,理解ができないと思うので,次回,非クラスター化インデックスの内部構造を解説する時に一緒に解説します。
次回は非クラスター化インデックスの内部構造を解説するなかで,IndexSeekがどういった動作なのか,そして,RIDLookupがどういった動作をしているのか?という事を解説していきます。
#S1_01_はじめに
#S1_02_インデックスとは
#S1_03_インデックスの有無実演
#S1_04_SQLServerのインストール
#S2_01_データベースとテーブルの作成
#S2_02_データの作成
#S2_03_全件検索
#S2_04_キャッシュとは
#S2_05_検索条件ありで検索
#S2_06_テーブルスキャンとは
#S2_07_インデックスの種類
#S2_08_非クラスター化インデックスの作成
#S2_09_非クラスター化インデックスの内部構造
#S2_10_インデックスのない列の検索とインデックスの有効化無効化
#S2_11_クラスター化インデックスの作成
#S2_12_クラスター化インデックスの内部構造
#S2_13_クラスター化インデックスの検索
#S2_14_インデックスの検索補足
#S2_15_付加列インデックス
#S2_16_プライマリキーとユニークキー
#S2_17_インデックス作成手順
#S2_18_インデックスの注意点
おわりに
参考図書
SQL
・SQL Server Transact-SQLプログラミング 実践開発ガイド
・SQLクックブック 第2版 ―データベースエキスパート、データサイエンティストのための実践レシピ集
・達人に学ぶSQL徹底指南書 第2版 初級者で終わりたくないあなたへ
・SQL Server 2016データベース構築・管理ガイド Enterprise対応
設計
内部構造
・アドバンストMS SQL SERVER 2008 構築・管理 (マイクロソフトコンサルティングサービステクニカルリファレンスシリーズ)