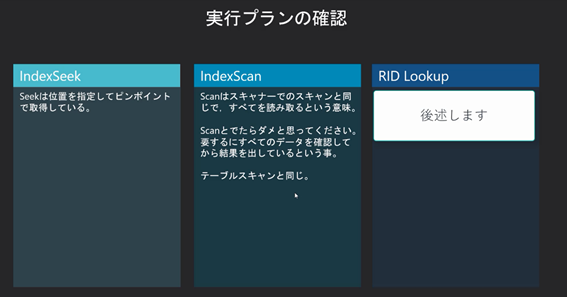
前回は非クラスター化インデックスを作って,実行プランでは「IndexSeek」と「RIDLookupになっていることを確認しました。前述した通り,SeekかScanに注目し,Scanなら全部読んでしまっている,Seekならピンポイントでうまく動いていると解釈してください。
Scanには「TableScan」だけでなく「IndexScan」というのも存在し,Indexとついているから,Indexがうまく動作しているように誤解するかもしれませんが,「Scan」なので,インデックスをすべて読んだという意味になります。これも,ポイントでは見つけられず,すべてを読んだということなので,インデックスをうまく使えていない状態です。
非クラスター化インデックスの内部構造
実表データ
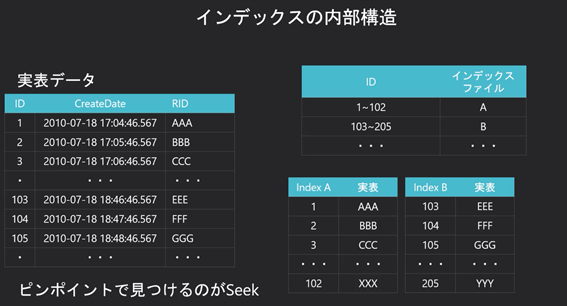
非クラスター化インデックスの内部構造としては,まず,実表データ領域というものがあります。これはそのまま実際のデータで,SQLServerでは8キロバイトごとのファイルが複数ある形で存在しています。インデックスがない場合はこの実表データのみが存在していることになります。
非クラスター化インデックスを作成すると
非クラスター化インデックスを作成する,インデックスファイルが作成されます。今回のようにIdでインデックスを作成すると,Idの順序でインデックスファイルが作られます。インデックスファイルは,ツリー構造になっていて,「1~102」までは「インデックスファイルA」にあるよって感じで,次にインデックスAファイルを読むと「1から50はインデックスファイルA2にあるよ」って感じで,たどれるようになっています。そのインデックスファイルをたどっていくと,インデックスの終端があり,これを「リーフページ」と呼んでいます。
リーフページ
リーフページはインデックスの項目とRIDが入っています。今回の例であれば,Idのインデックスなので,「Id」と「RID」が入っていて,1~50までのIdとRIDが入っているという感じです。
RID
RIDとは実表データの行情報です。インデックスのリーフページには「Id」と「RID」しかないので,実表データから,社員データの姓名などを取ってこないといけません。そのために実表データがどのファイルの何行目にあるかという情報が入っています。先述の通り,実表データは8キロバイトの大量のファイルの集まりなので,どのファイルの何行目にデータがあるという情報があれば,ピンポイントでデータを取得することができます。こうやってインデックスファイルをツリー状にたどって,リーフページに行きつくことをIndexSeekといいます。要するに,インデックスをツリー状にたどり,ピンポイントにRIDを取得することで,どのファイルの何行目に欲しいデータがあるという事が分かります。そして,このRIDから必要なデータを取得することをRIDLockupといいます。
RIDLockup
インデックスのリーフページのRIDから実データの所在を割り出し,データを取りに行くことを,RIDLookupといい,社員テーブルをId指定で検索したときに,IndexSeek+RIDLookupになっていたという事は,「Id=1」で非クラスター化インデックスを探索し,ピンポイントでリーフページたどり着いたことをIndexSeekといい,そのIndexSeekしたリーフページにあるRIDで実データの場所を割り出し,実データを取りだしたことをRIDLookupと呼んでいます。なので,今回の非クラスター化インデックスは期待通りに機能したという事になります。
非クラスター化インデックスの内部構造(別表)
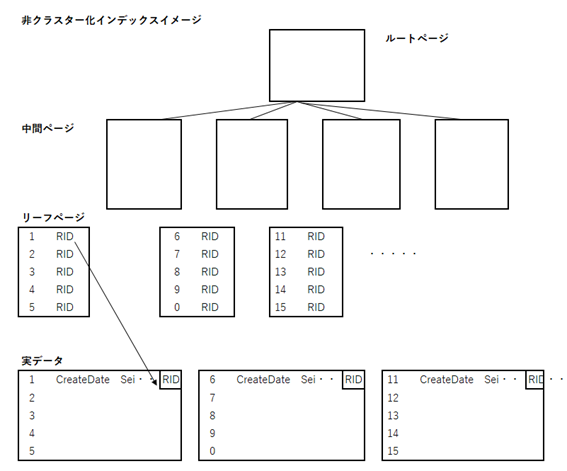
非クラスター化インデックスの内部構造を別の図で示します。前述の通り,ルートページからId順でたどり,リーフページにたどり着いた後に,RIDで実データを取得するという構造になります。
#S1_01_はじめに
#S1_02_インデックスとは
#S1_03_インデックスの有無実演
#S1_04_SQLServerのインストール
#S2_01_データベースとテーブルの作成
#S2_02_データの作成
#S2_03_全件検索
#S2_04_キャッシュとは
#S2_05_検索条件ありで検索
#S2_06_テーブルスキャンとは
#S2_07_インデックスの種類
#S2_08_非クラスター化インデックスの作成
#S2_09_非クラスター化インデックスの内部構造
#S2_10_インデックスのない列の検索とインデックスの有効化無効化
#S2_11_クラスター化インデックスの作成
#S2_12_クラスター化インデックスの内部構造
#S2_13_クラスター化インデックスの検索
#S2_14_インデックスの検索補足
#S2_15_付加列インデックス
#S2_16_プライマリキーとユニークキー
#S2_17_インデックス作成手順
#S2_18_インデックスの注意点
おわりに
参考図書
SQL
・SQL Server Transact-SQLプログラミング 実践開発ガイド
・SQLクックブック 第2版 ―データベースエキスパート、データサイエンティストのための実践レシピ集
・達人に学ぶSQL徹底指南書 第2版 初級者で終わりたくないあなたへ
・SQL Server 2016データベース構築・管理ガイド Enterprise対応
設計
内部構造
・アドバンストMS SQL SERVER 2008 構築・管理 (マイクロソフトコンサルティングサービステクニカルリファレンスシリーズ)